
Hello there, I’m Obafemi 
I’m a 4th year PhD candidate at Karen Panetta’s Vision Sensing and Simulation Lab at Tufts University, where I work on computer vision, multimodal machine learning and generative AI to address complex, real-world problems.
Research
My research is centered on developing cutting-edge machine learning, and deep learning techniques for vision and multimodal understanding (vision-language), toward deploying reliable, robust, and trustworthy models that achieve state-of-art performance.
 Attention-based two-stream high-resolution networks for building damage assessment from satellite imagery.
Attention-based two-stream high-resolution networks for building damage assessment from satellite imagery.
Victor Oludare, Landry Kezebou, Obafemi Jinadu (corresponding author), Karen Panetta, Sos Agaian: In Multimodal Image Exploitation and Learning 2022 (Vol. 12100, pp. 224-239). SPIE, 2022.
Poster Presentation
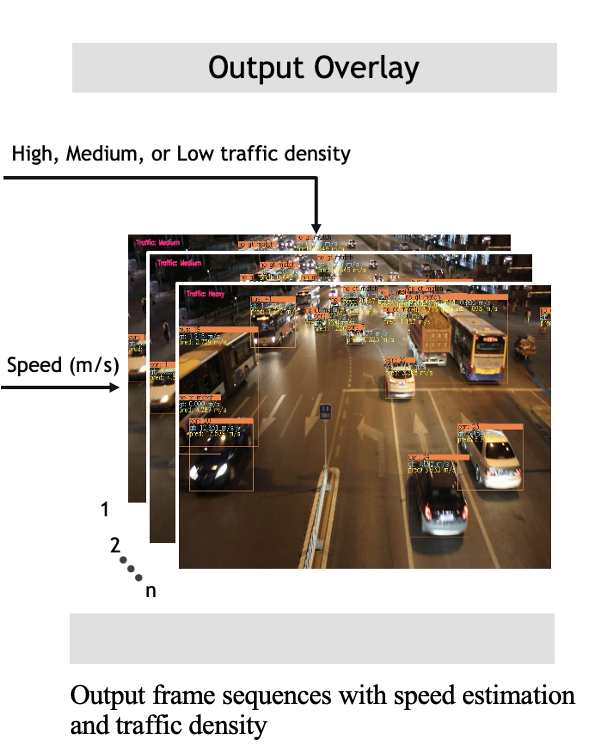 Instant-level vehicle speed and traffic density estimation using deep neural network.
Instant-level vehicle speed and traffic density estimation using deep neural network.
Obafemi Jinadu (corresponding author), Victor Oludare, Srijith Rajeev, Landry Kezebou, Karen Panetta, Sos Agaian: In Multimodal Image Exploitation and Learning 2023, vol. 12526, pp. 125-138. SPIE, 2023.
Poster Presentation. Project GitHub repository can be found here
 An Impact Study of Deep Learning-based Low-light Image Enhancement in Intelligent Transportation Systems.
An Impact Study of Deep Learning-based Low-light Image Enhancement in Intelligent Transportation Systems.
Obafemi Jinadu (corresponding author), Srijith Rajeev, Karen Panetta, Sos Agaian: In Multimodal Image Exploitation and Learning 2024 (Vol. 13033, pp. 154-171). SPIE. Project GitHub repository can be found here
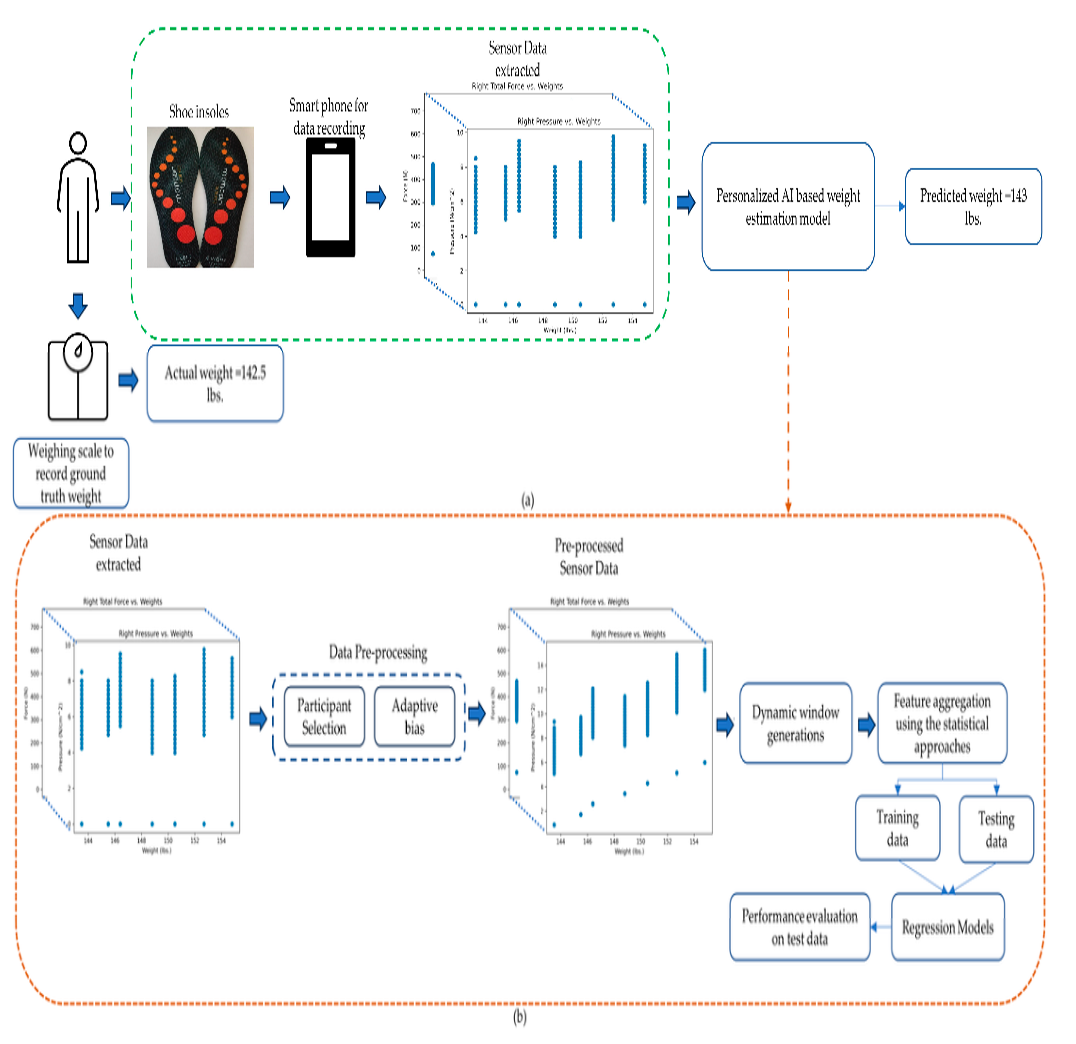 An Individualized Machine Learning Approach for Human Body Weight Estimation Using Smart Shoe Insoles.
An Individualized Machine Learning Approach for Human Body Weight Estimation Using Smart Shoe Insoles.
Foram Sanghavi, Obafemi Jinadu, Victor Oludare, Karen Panetta, Landry Kezebou, Susan B. Roberts: Sensors 2023, 23(17) Special Issue Wearables and Artificial Intelligence in Health Monitoring.
Personal & Course-based Machine Learning Adjacent Projects
- My DDPM re-implementation (Github Repository here).
I re-implemented the paper denoising diffusion probabilistic model (DDPM) from scratch. The repository explores the strengths and weaknesses of DDPMs along with some ablation studies. - VisionTransformer (ViT) Re-implementation from Scratch (Github Repository here).
I re-implemented the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scalefrom scratch. The repository explores the Vision Transformer Architecture in detail, mapping the theory into code and thus cementing my understanding of the components that make up this architecture. Probabilistic Model for Amur Tiger Re-identification my paper | course website
I developed an animal re-identification deep-learning model that classifies 107 amur tiger entities using a Maximum A Posteriori (MAP) estimation model to counter the overfitting challenge of traditional maximum likelihood estimation-based models with severely limited and imbalanced training data.
Instructor comment: “very nice overall! Would be excited to talk more if you want to follow up on this project. I think could be a great potential future CP for this class, among other things (maybe also a cool research paper)” ~ Michael C. HughesStatistical Pattern Recognition, Spring 2023Score 104/100Grade A- Unified Self-Supervised Algorithm for Speech, Vision, and Text: Meta’s data2vec Project paper re-write here. Adapted from original paper
Machine Learning, Spring 2022Grade A+ - Natural Language Processing in Classifying Review Sentiment with Bag-of-Words Features project documentation
Machine Learning, Spring 2022Grade A+
Recent News & Updates
Preprint version of our paper titled “A Unified Approach to Pose Estimation in Elephants and Other Quadrupeds using Noisy Labels” has been posted on Research Square.
April 9, 2025I am a recipient of the 2024 IEEE Signal Processing Society Scholarship Award.
September 27, 2024I was awarded the 2024 School of Engineering Outstanding Academic Scholarship Award at Tufts University! (one of four students bestowed this award).
March 26, 2024I was awarded the 2024 School of Engineering Outstanding Academic Scholarship Award at Tufts University! (one of four students bestowed this award).
March 26, 2024Our paper ‘An impact study of deep learning-based low-light enhancement in intelligent transportation systems’ has been accepted.
April 27, 2024Presentation at Multimodal Image Exploitation and Learning conference SPIE Defense + Commercial SensingDeveloping an image-text pair dataset tailored for transportation.
work in progressStay tuned!Developing a dataset tailored for animal conservation and an accompanying deep-learning architecture for pose estimation. Soon to be published.
work in progressStay tuned!